
Creating and sharing your own immersive, virtual journeys for experiential learning
introduction
We present CrowdVR 360, a system for collaboratively creating and sharing
educational VR content. CrowdVR 360 consists of two elements: an iOS app
for students to view panoramas and a web interface for teachers to annotate
panoramas. We compare traditional paper materials with our VR platform,
analyzing differences in learning outcomes and user experience.

Figure 1: Grand Canyon Desktop View in CrowdVR 360
Related Work
Google Expeditions
A series of well-curated annotated panoramas. VR application has two views - one for students to see panorama, and one for teacher that includes information to point out about specific locations. Teachers can guide users to look at each point and relay the provided information. Users cannot create their own scenes or annotations.
ThingLink
A tool for annotating 360 images. Only offline so users can't collaborate and no mobile app for users to view in VR.
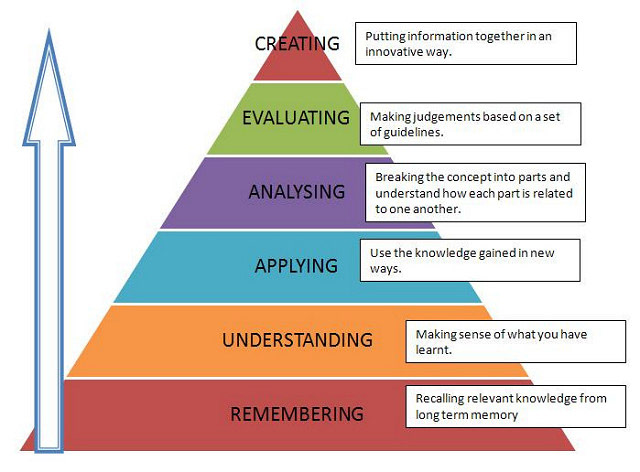
Figure 2: Six Levels of Cognitive Learning
Krathwohl's revised Bloom's Taxonomy
Serving as a framework for organizing and understanding the dierent types
of learning, Krathwohl's revised Bloom's Taxonomy[1] ordered cognitive learning into six levels: remembering, understanding, applying, analyzing, evaluating and creating. In our user study, we primarily focus on the processes of remembering, which includes recognizing and recalling information, and understanding, which includes interpretation and inference in order to make meaning of information.
Supporting Learning with Spatial Visualizations
Relevant to our focus of utilizing spatial information , previous studies have provided evidence that spatial features can be learned automatically, without conscious, intentional focus (e.g., Mandler et al., 1977)[2]. Combining this theory of automatic spatial processing with the concept of spatial indexing, which is based on the idea that locations can be used to help access other information(Pylyshyn, 1989)[3], we hypothesize that spatial information presentations can be used to support experiential learning in Virtual Reality.
System Design
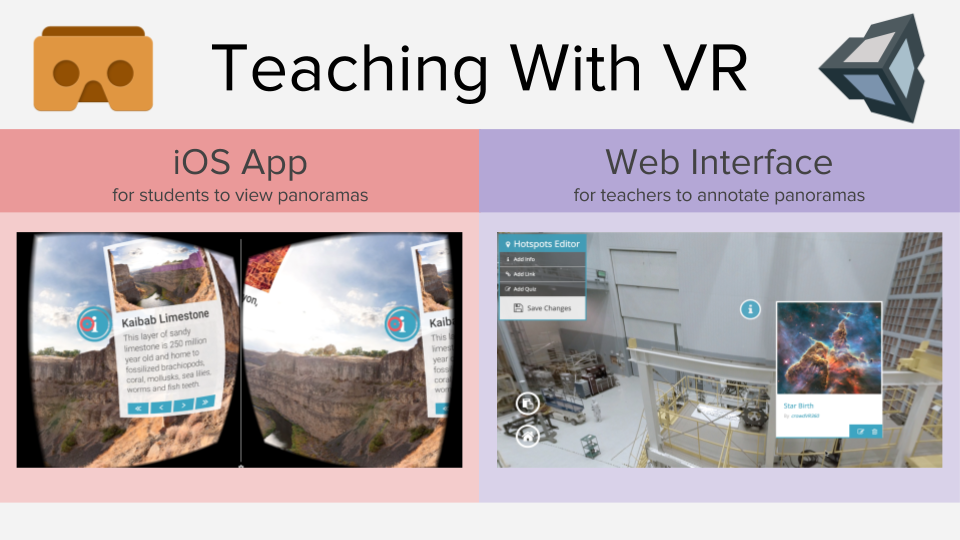
Figure 3: Overview: Mobile App and Web App
CrowdVR 360 consists of two elements: an iOS app for students to view panoramas and a web interface for teachers to annotate panoramas. Users upload panoramas and can synchronously annotate them from multiple devices, allowing crowdsourced content creation. Three annotation types are supported: info(image and text), quizzes (question and answers), and links (between panoramas).
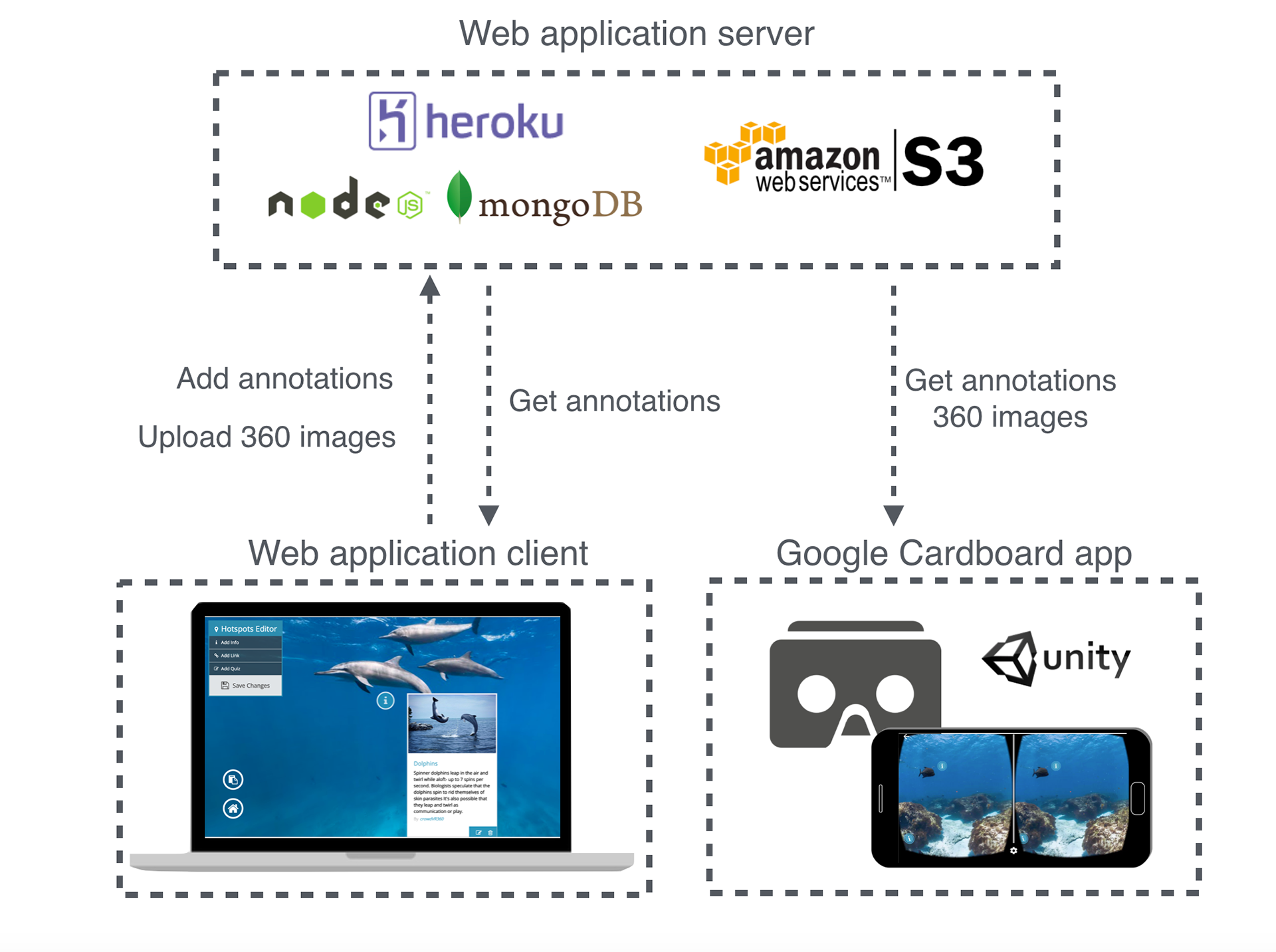
Figure 4: CrowdVR 360 System Architecture

Figure 5: Three Types of Annotations
Students can view all panoramas and corresponding annotations using our iOS
/ Android app and their VR headset of choice.
Methodology
We evaluated the learning outcomes of CrowdVR 360 by comparing it with
traditional paper materials. Participants learnt about two locations: Fernando De Noranho and Mount Fuji, before being tested on what they could remember.
Participants. We recruited 20 participants (9 female, 11 male), aged 19 to
26 (mean: 22.3) from Cornell University. Almost one third of them had no previous experience in VR. Backgrounds included computer science, information science, communication and system engineering.
Materials. Panoramas and annotations were taken directly from Google Project Expeditions. Each location consisted of three distinct scenes. Each scene had three location specific annotations consisting of text and a related image. Annotations were consistent between the VR and paper versions of each location.
Procedure. The study was split into three parts: material learning, location recall and a post-test.
1. Studying Materials
Each participant viewed both locations, one in VR and one on paper.
The order with which they viewed locations and the medium with which
they viewed them was randomized for individual participants and balanced
across the study. For each location, they were instructed to learn each of
the 3 annotations as well as possible before proceeding to the next scene.
They were not allowed to go back to prior scenes in VR or on paper. Time
spent learning was tracked in both cases.
2. Spatial Recall
Participants were shown each scene again and asked to recall the location
of the annotations they had previously seen. The number of successfully
recalled locations was recorded.
3. Post-test
Participants answered three multiple-choice questions and one open-ended
question per scene, for a total of twelve questions per location. A series
of likert-scale questions followed, evaluating user experience and learning
preferences between the two media. Finally, participants were asked for
general feedback and suggestions.
Results
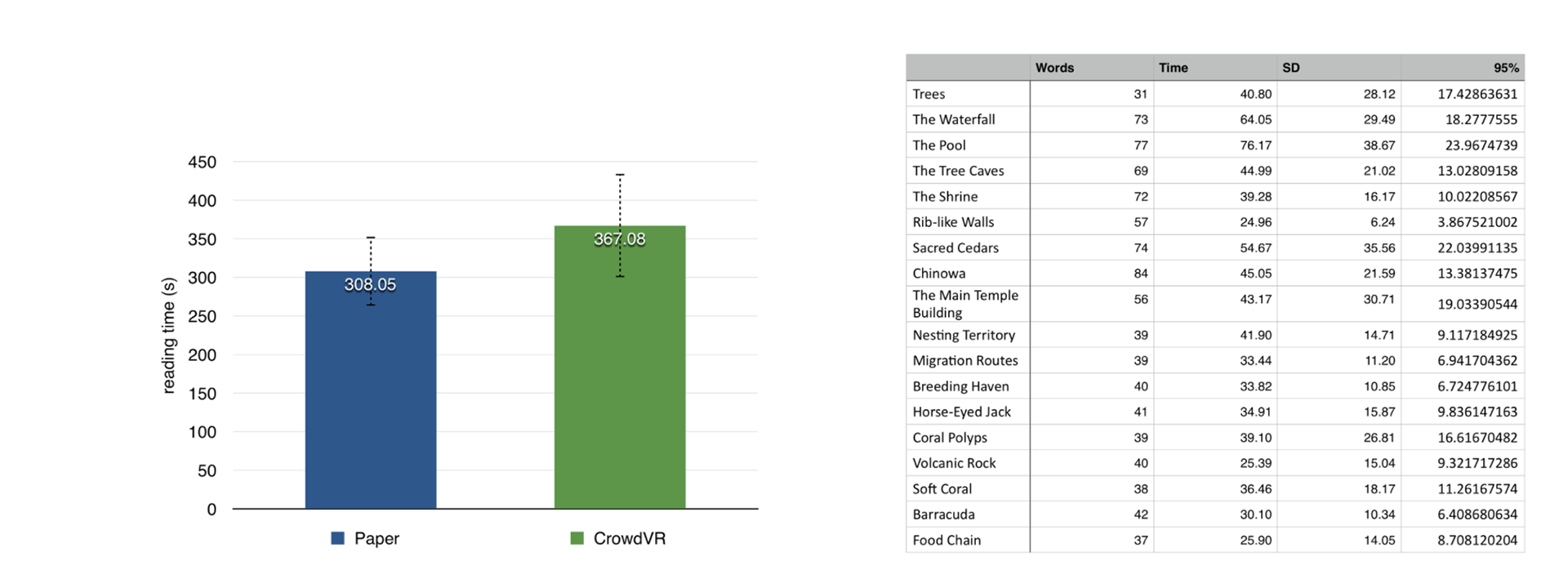
Figure 6: (left) reading time in both conditions. (right) reading time per annotation in CrowdVR
Performance: reading time
Normality testing of reading time suggested paper material reading time was
normally distributed (p=0.899), but not CrowdVR 360 reading time (p=0.018).
To account for this non-normal data, we analyzed the data with paired-samples sign test rather than a paired t-test.
As shown in Figure 6(left), there was no significant difference between reading time for Paper materials and CrowdVR (p=0.824) and mean reading times were 5min 8s and 6min 7s, respectively. The result suggested reading in VR environment can be as effective as reading the paper material.
Figure 6(right) showed the average reading time for each annotation in CrowdVR condition. Overall, the result suggested people can read 78 words per minute with CrowdVR.
Remembering: spatial recall and factual recall
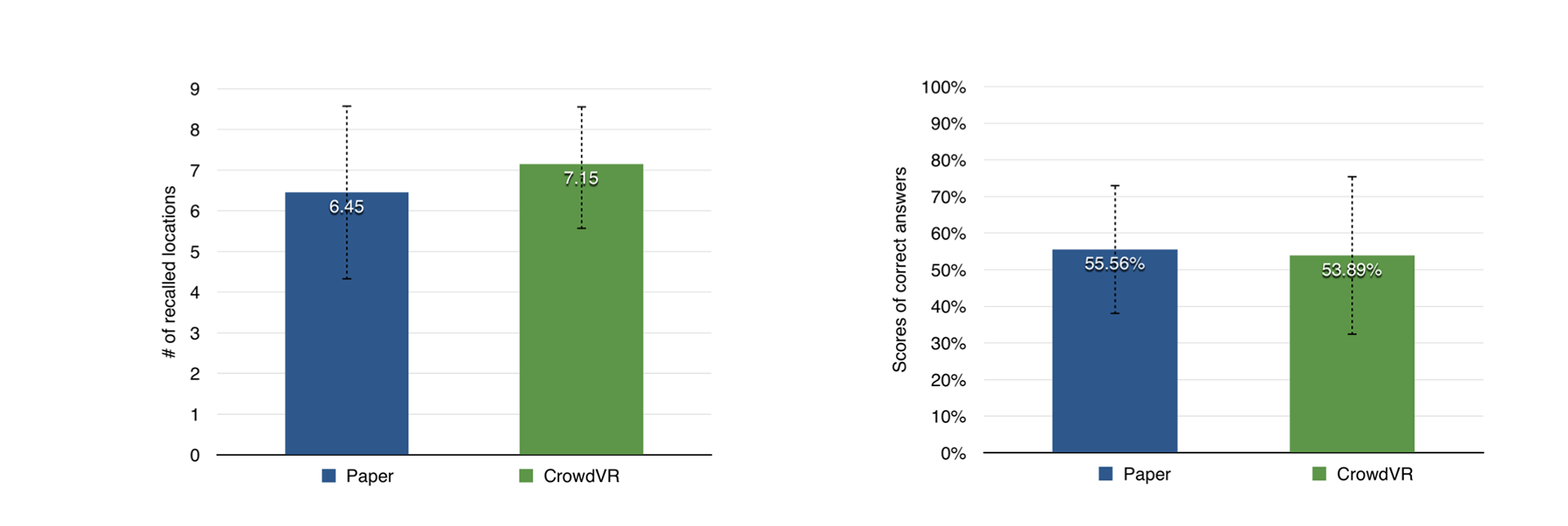
Figure 7: (left) spatial recall in both conditions. (right) factual recall in in both conditions.
According to Krathwohl's revised version of Bloom's Taxonomy[1], the first level of cognitive process is remembering, which includes recognizing and recalling information. To evaluate how users performed in terms of remembering between the 2 different learning materials, we first calculated how many annotation locations they could recall in an empty panorama image.
Since the data in the CrowdVR condition is not normally distributed (p= 0.116), we analyzed the data with paired-samples sign test. Figure 7(left) shows that, after reading all 9 annotations in each condition, people can recall more annotation locations with CrowdVR (mean: 71.67%) than with paper materials (mean:79.44%). However, this difference was not statistically signficant (p=0.359).
To understand the learning outcome, we also calculated the number of cor-
rect answers for our post-test questions. As shown in Figure 7(right), people answered roughly 54% questions correctly in both conditions with no significant difference between paper materials and CrowdVR (p= 0.629).
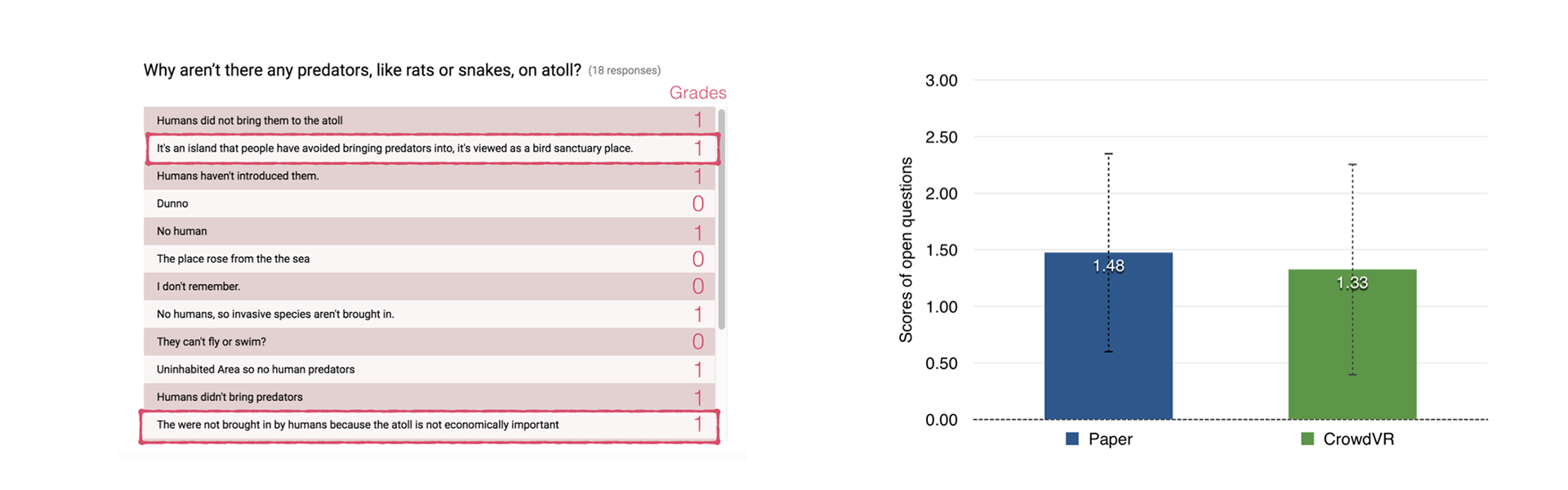
Figure 8: (left) spatial recall in both conditions. (right) factual recall in in both conditions.
In terms of the open-ended question, as shown in the Figure 8(left), we first manually graded the participants' answers. The result showed that there was no significant difference between paper and CrowdVR condition. According to the feedback from the participants, answering these open-ended questions was quite challenging since it was really hard for them to memorize all the details during the study. However, some participants still can came up with a thorough as the 2 highlighted answer in Figure 8(left)
User experience
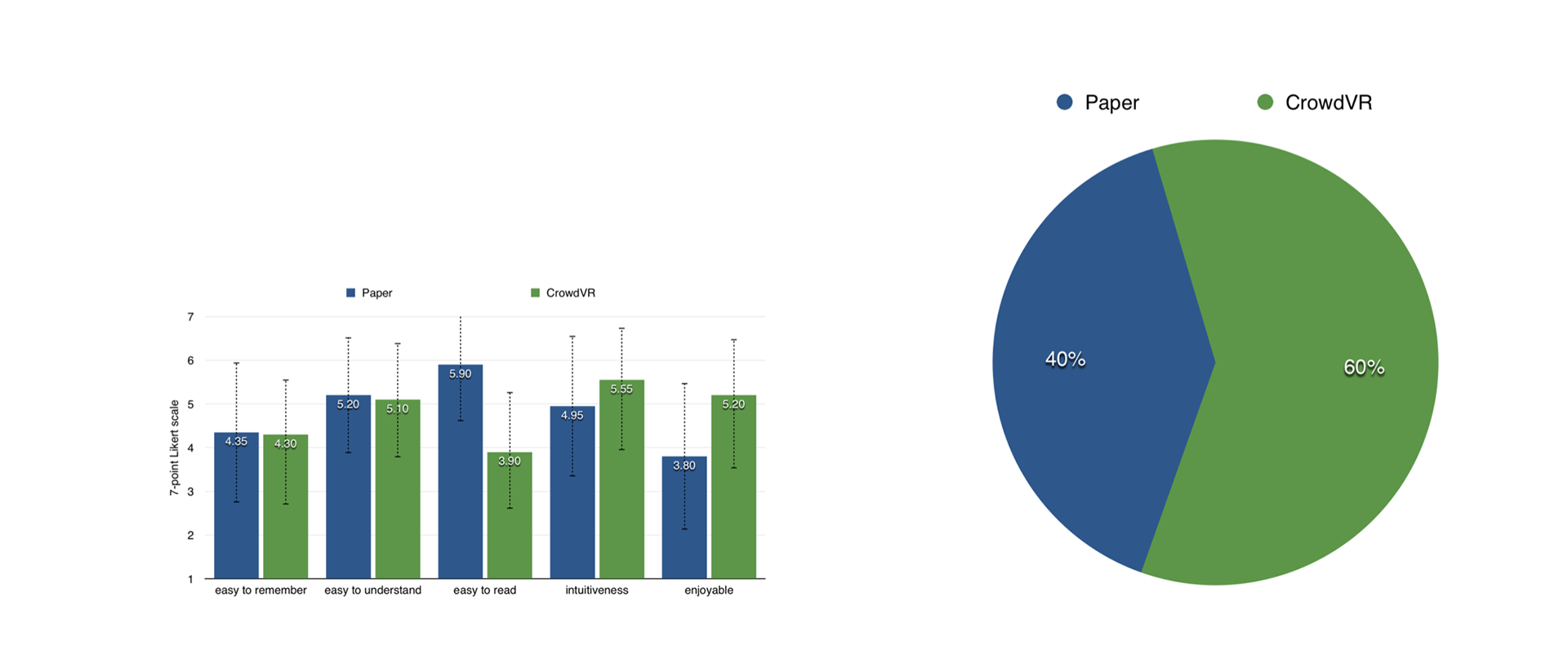
Figure 9: (left) subject rating comparing CrowdVR with paper material. (right) users’ preferred learning materials
According to the Technology Acceptance Model (TAM) [1], when users are presented with a new technology, a number of factors infuence their decision about how and when they will use it, including perceived usefulness and perceived ease-of-use. We designed 5 7-point Likert scale questions in our post-test to assess these 2 factors.
In terms of perceived usefulness, Figure 9 (left) demonstrated there was no
significant difference regarding "easy-to-remember" and "easy-to-understand" aspects. Most of the participants thought the content was hard to remember in the limited time, regardless of learning format.
As for perceived ease-of-use, as shown in Figure 9 (left), when looking at participants' perception in "easy-to-read," "intuitiveness," and "enjoyable" aspects, results suggested learning with CrowdVR was more enjoyable and more intuitive.
There was a significant difference in "enjoyable" aspect (Wilcoxon Signed-Rank Test, z=-2.442, p=0.015 < 0.05). However, participants considered reading with CrowdVR to be significantly more difficult than with paper materials (Wilcoxon Signed-Rank Test, z=-3.377, p=0.001 < 0.05).
Overall, when asked about the preferred learning material, 60% of the users
chose CrowdVR over the paper material (40%), as shown in Figure 9(right).
Discussion
General feedback from our user study fell into 5 main categories: nausea, reading difficulty, interactivity, novelty and content design. We received further feedback by sharing our website on reddit and Google+.
Nausea
"I feel dizzy in the VR, especially when I turn my head around quickly."
"The VR was not very comfortable."
"The image in the screen often shifted even though I wasn't moving, making me dizzy."
By deploying our VR app on phones using google cardboard, we sacrficed user
experience in favor of accessibility. As technology improves, we expect the experience to improve and dizziness to subside (it is already rare in high-end VR displays like the HTC Vive).
Reading Difficulty
"It was a hard to read the materials when using the VR. . . I couldn't figure out how the look by scrolling worked."
"Difficult for user to change pages."
Many users found the VR text interface cumbersome. Whilst users could see
all the text at once on paper, they had to scroll between pages in VR. This
required selecting buttons via gaze, which many users found unintuitive. How to best display large amounts of text in VR is an open-ended question. Possible improvements to our method include: displaying all text at once, intelligently scrolling based on gaze, using a system with button or controller input.
Interactivity
"Using movement to invigorate the objects in the VR (such as swimming sh,
nesting the coral) could have also aided memory"
"Using VR for education would be more eective if the users were quizzed as
they went through each location. At the end of each location if I were quizzed I would feel more inclined to remember the information I was taking in."
Our system allows for quizzes but they were not included in the user study
for simplicity. It'd be interesting to see if the effectiveness of quizzes differs between media. More complex content, such as animations and incorporating 3D models would undoubtedly increase memorability but also require more upfront effort from the teacher to create and falls outside the current scope of our system.
Novelty
A third of our users had no prior experience with VR, leading to a learning-curve with the gaze-based interactions, as well as a strong novelty. One user remarked: "As a first time user I found I was more focused on the actual use of the headset and getting used to VR than the actual study material. So in a way the medium was a distraction. But it was a much more enjoyable learning experience. So I think maybe if I was more used to VR I may have scored better for that section."
It is unclear how the novelty of VR impacted our results and whether they
would hold with repeated use. It is possible that as users gain experience and become proficient with VR, enjoyment from novelty would diminish but learning outcome would increase.
Content Design
Despite our best efforts to design content that best afforded itself to learning in VR, our study might have counteracted these efforts:
"The 'feeling that you were there' test was nice, but didn't really connect well with the task. Since my task was to focus on the text, I mostly just jumped from one text-box to another."
We hypothesize that VR better facilitates spatial understanding which can lead to greater recall. Creating spatially dependent content, however, is challenging and requires expert knowledge of an environment. In designing content, we initially set up scenes where users could navigate continuously through space (akin to google street-view), however, without expert knowledge, it proved difficult to design location-specific content. In most cases, the same small number of locations were notable, irrespective of perspective. As such, moving through environments provided limited new opportunities for location-dependent annotations. It was much easier to design new content by changing between environments completely, as we did in our study, sacrificing spatial cohesion.
Distribution
We also deployed our web application on heroku and shared it on Reddit EdTech and with Google+ communities such as Google cardboard for education.
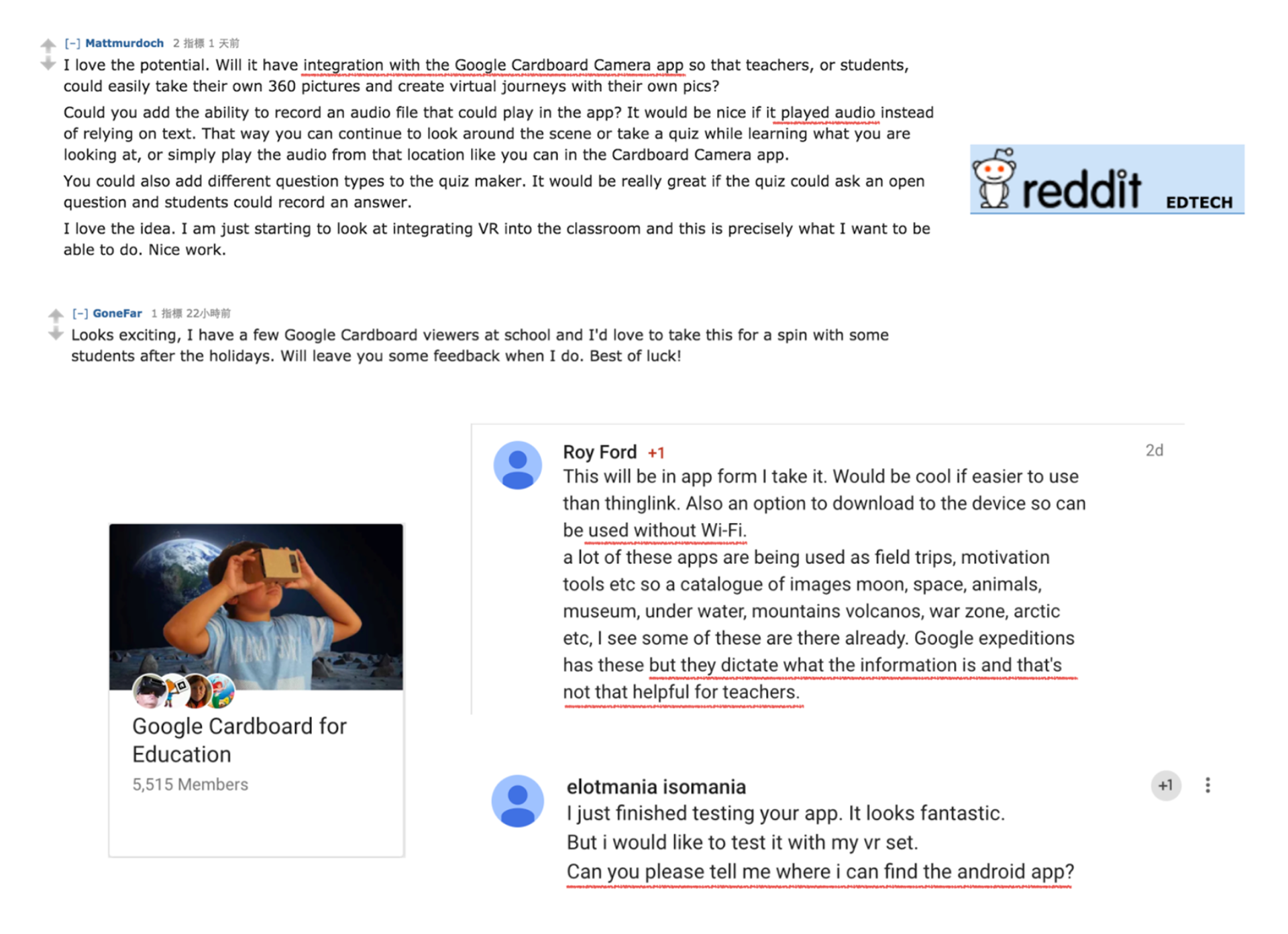
Figure 10: Feedback from Reddit and Google+
Feedback was positive, praising the ability for teachers to easily create content, providing suggestions for further features, and inquiring about the app (which was yet to be released).
Conclusions
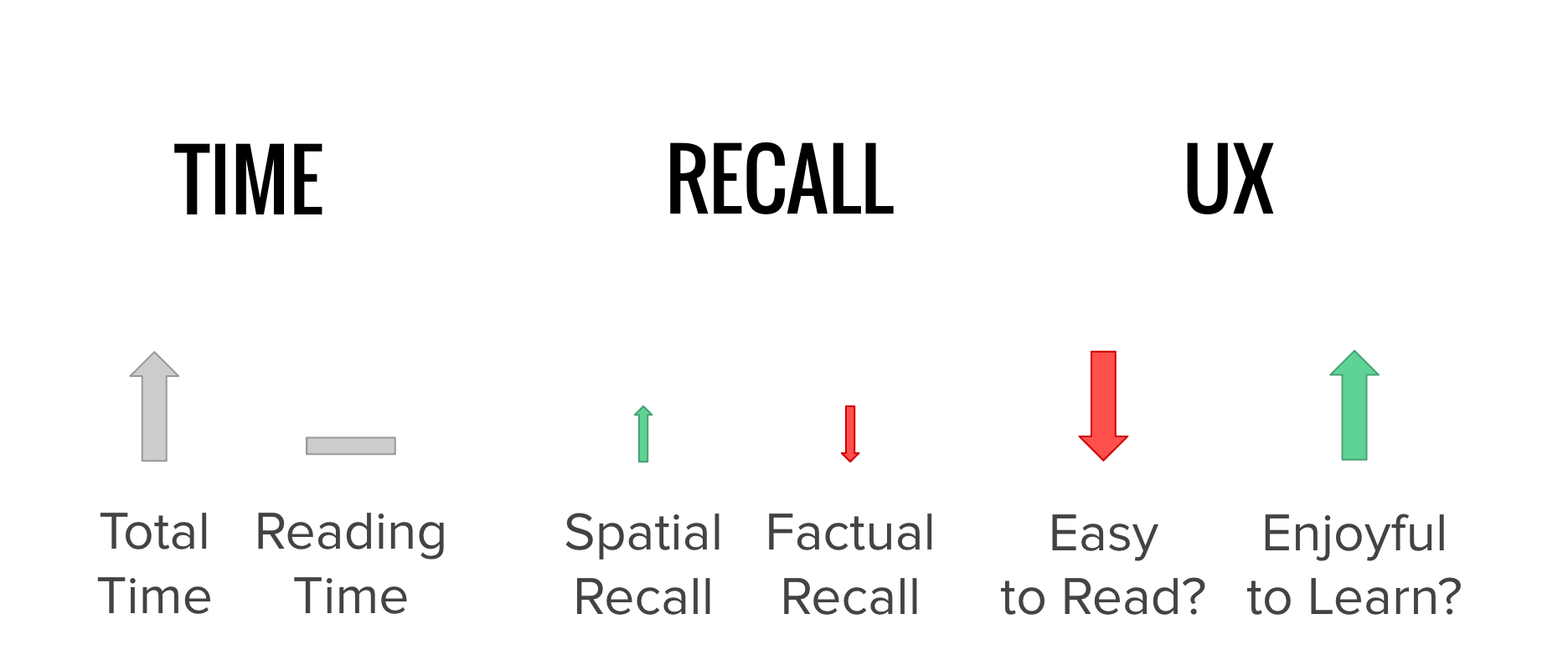
Figure 11: Conclusions on time, recall, and user experience
CrowdVR 360 aims to make educational VR content as accessible as possible by providing a system for collaboratively creating, sharing and annotating panoramas. Compared to paper, our users spent more time learning but the same amount of time reading annotations. Their spatial recall increased slightly whilst factual recall decreased slightly. Finally, users found annotations hard to read but enjoyed the overall experience more.
To best leverage CrowdVR 360 as a learning platform we recommend location-
specific content, taking advantage of users improved abilities of spatial recall and extra time spent observing the wider environment. Designing such content can be challenging, however, we will be further sharing our system and look forward to seeing what others can create. We believe the extra enjoyment and immersion from our system can be valuable, even if educational outcome is otherwise immeasurable.
Video
References
[1] D. R. Krathwohl. A Revision of Bloom’s Taxonomy: An Overview. Theory into Practice, 41(4):212–218, 2002.
[2] Seegmiller D. Day J. Mandler, J. M. On the coding of spatial information. Memory Cognition, 5(1):10–16, 1977.
[3] Z. Pylyshyn. The role of location indexes in spatial perception: A sketch of the FINST spatial-index model. Cognition, 32(1):65–97, 1989.